This tutorial will help you to run a wordcount mapreduce example in hadoop using command line. This can be also an initial test for your Hadoop setup testing.
1. Prerequisites
You must have running hadoop setup on your system. If you don’t have hadoop installed visit
Hadoop installation on Linux tutorial.
2. Copy Files to Namenode Filesystem
After successfully formatting namenode, You must have start all Hadoop services properly. Now create a directory in hadoop filesystem.
$ hdfs dfs -mkdir -p /user/hadoop/input
Copy copy some text file to hadoop filesystem inside input directory. Here I am copying LICENSE.txt to it. You can copy more that one files.
$ hdfs dfs -put LICENSE.txt /user/hadoop/input/
3. Running Wordcount Command
Now run the wordcount mapreduce example using following command. Below command will read all files from input folder and process with mapreduce jar file. After successful completion of task results will be placed on output directory.
$ cd $HADOOP_HOME $ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar wordcount input output
4. Show Results
First check the names of result file created under dfs@/user/hadoop/output filesystem using following command.
$ hdfs dfs -ls /user/hadoop/output
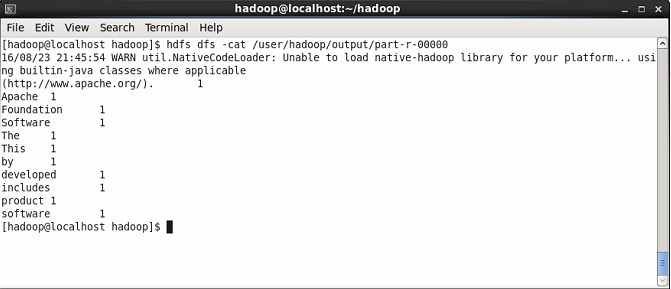
Now show the content of result file where you will see the result of wordcount. You will see the count of each word.
$ hdfs dfs -cat /user/hadoop/output/part-r-00000
Thanks for Visit Here

Comments
Post a Comment